

Text to Speech 💻🔊 TTS – 1
El Text to Speech (TTS) es una tecnología que convierte texto escrito en voz hablada de forma artificial. En un mundo donde el consumo de contenido se diversifica cada vez más, el TTS ha cobrado protagonismo en sectores como la accesibilidad, la automatización, la educación y el marketing digital. Su evolución ha sido tan impactante que hoy es posible crear voces naturales, expresivas y personalizadas con ayuda de la inteligencia artificial.

Fundamentos del TTS
Para entender cómo funciona la tecnología Text to Speech, es fundamental conocer su base técnica y evolución. El TTS no se limita a leer texto en voz alta, sino que implica una serie de procesos complejos que transforman palabras escritas en audio natural y comprensible. Esta sección te llevará desde el concepto básico hasta la forma en que el sistema analiza, interpreta y vocaliza el contenido, revelando cómo ha pasado de voces robóticas y planas a soluciones avanzadas que imitan la entonación y expresividad del habla humana.
¿Qué es Text to Speech?
Es una tecnología de síntesis de voz que toma un texto escrito y lo transforma en audio mediante un sistema computacional. Se utiliza en dispositivos, apps, sitios web, y plataformas de inteligencia artificial.
Cómo funciona: del texto a la onda de sonido
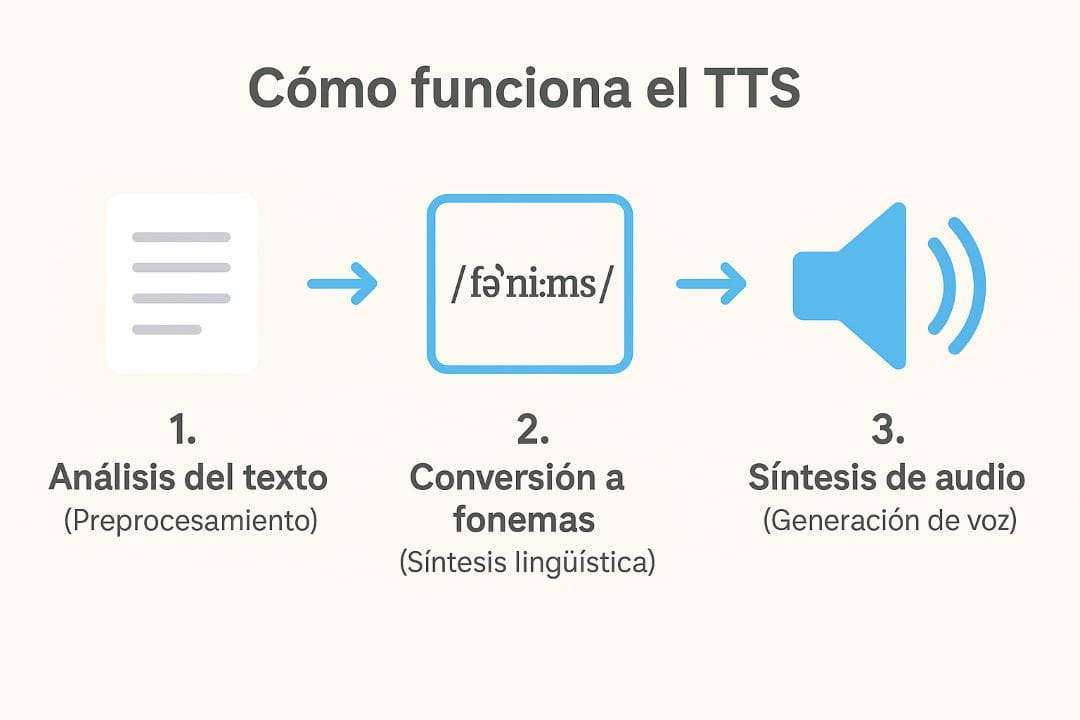
El proceso de conversión de texto a voz puede parecer sencillo desde fuera, pero involucra múltiples capas de procesamiento lingüístico y sonoro. En términos generales, el funcionamiento del TTS se puede dividir en tres pasos fundamentales:
- Análisis del texto (Preprocesamiento)
El sistema comienza analizando el contenido textual. Esto incluye la segmentación de frases, detección de puntuación, interpretación de símbolos, números y abreviaturas, así como la identificación del idioma y contexto gramatical. Este paso asegura que el texto sea correctamente comprendido por el motor de voz. - Conversión a fonemas (Síntesis lingüística)
Una vez analizado, el texto se convierte en una secuencia de fonemas, que son las unidades mínimas de sonido en un idioma. En esta etapa se determinan también la entonación, el ritmo y la acentuación, simulando cómo lo pronunciaría un hablante humano. - Síntesis de audio (Generación de voz)
Finalmente, el sistema transforma los fonemas y la prosodia en una onda sonora. Dependiendo de la tecnología utilizada, esto puede hacerse mediante fragmentos grabados de voz humana o, en sistemas más modernos, mediante redes neuronales que generan audio de alta calidad en tiempo real. El resultado es una voz artificial que puede leer el texto con fluidez y naturalidad.
Historia breve del TTS: de lo robótico a lo humano
La tecnología de Text to Speech (TTS) comenzó con voces robóticas, mecánicas y monótonas, propias de los primeros sistemas computarizados en los años 50 y 60. Estos primeros motores generaban sonidos artificiales que resultaban difíciles de entender y poco naturales.
Con el avance de la inteligencia artificial y el procesamiento del lenguaje, el TTS ha evolucionado hacia voces cada vez más humanas, capaces de reproducir entonaciones, emociones y ritmos propios del habla natural.
Hoy en día, gracias a redes neuronales y modelos avanzados de síntesis, la tecnología TTS ofrece experiencias auditivas casi indistinguibles de una voz humana real. Las voces pueden imitar tonos, pausas e incluso emociones humanas, acercándose cada vez más a una conversación real, ampliando sus aplicaciones en la accesibilidad, asistencia virtual y creación de contenido multimedia.
Tipos de Tecnologías Text to Speech
El desarrollo del Text to Speech ha pasado por diferentes generaciones tecnológicas, desde sistemas rudimentarios hasta plataformas impulsadas por inteligencia artificial generativa. Comprender los distintos enfoques utilizados en la síntesis de voz permite identificar qué tipo de solución es más adecuada según el uso o el nivel de calidad deseado. Exploremos brevemente las principales tecnologías detrás del TTS, desde los modelos basados en reglas hasta las herramientas modernas que imitan el habla humana con sorprendente realismo.
Síntesis de voz basada en reglas
Un enfoque clásico que se basa en normas lingüísticas preprogramadas.
Este método clásico, también conocido como Rule-Based TTS, funciona mediante un conjunto de reglas lingüísticas y fonéticas predefinidas. El sistema analiza el texto y aplica normas gramaticales para generar la pronunciación adecuada. Aunque suena robótico y poco natural, aún se utiliza en dispositivos con recursos limitados o donde la prioridad es la velocidad y el bajo consumo de procesamiento, como lectores de pantalla básicos o sistemas embebidos.
Text to Speech con concatenación de fragmentos
Produce voces naturales pero es limitada en flexibilidad.
En este enfoque, conocido como Concatenative TTS, la voz se genera uniendo fragmentos reales de voz humana previamente grabados. Estos fragmentos (fonemas, sílabas o palabras) se seleccionan y combinan según el texto ingresado. Si bien la calidad puede ser bastante natural, su principal limitación es la rigidez: no permite mucha variación de entonación o expresión, y requiere grandes bases de datos de audio para cada idioma o voz.
Text to Speech con redes neuronales (Deep Learning)
Se basa en modelos de aprendizaje profundo que «aprenden» los patrones del habla. Permiten generar voces con gran naturalidad y adaptación a distintos estilos.
Con la llegada del aprendizaje profundo, los modelos neuronales han revolucionado la síntesis de voz. Tecnologías como Tacotron, WaveNet o FastSpeech permiten generar voz de manera completamente artificial, imitando con precisión la prosodia, el ritmo y la entonación del habla humana. Este tipo de TTS ofrece resultados mucho más naturales y expresivos, adaptándose incluso al contexto del texto. Además, requiere menos almacenamiento que la concatenación de clips reales.
Modelos modernos con IA generativa
Permiten clonar voces, expresar emociones y generar audios de alta calidad solo con texto.
Los sistemas más avanzados de TTS usan inteligencia artificial generativa, capaces no solo de sintetizar voz, sino también de clonarla, personalizarla y dotarla de emociones. Herramientas como ElevenLabs, Google TTS y MetaVoice permiten crear voces hiperrealistas que se adaptan a distintos estilos, tonos y contextos en tiempo real. Estos modelos pueden generar voz desde cero sin necesidad de grabaciones previas extensas, y abren la puerta a nuevas posibilidades en doblaje automático, asistentes personalizados y creación de contenido a escala.
Aplicaciones y Usos Comunes de Text To Speech
Desde asistentes virtuales hasta narradores automáticos en redes sociales, el TTS se está integrando en herramientas que usamos a diario. Las empresas lo utilizan para mejorar la experiencia del cliente, educadores para generar contenidos accesibles y creadores digitales para automatizar la producción de audio y video.
Accesibilidad y lectura asistida
Ideal para personas con discapacidades visuales o dificultades lectoras. Transforma contenido escrito en una experiencia auditiva accesible.
Automatización de procesos y bots
Usado en IVRs, asistentes virtuales, y sistemas automatizados de atención al cliente para ofrecer respuestas habladas en tiempo real.
Educación y e-learning
Permite crear cursos narrados automáticamente, audioguías, y material interactivo sin necesidad de grabaciones humanas.
Creación de contenido audiovisual
Los creadores de contenido usan TTS para generar voces en TikTok, YouTube, reels y podcasts sin tener que grabarse.
Experiencias personalizadas en apps y videojuegos
Los desarrolladores integran TTS para ofrecer voces interactivas en apps, juegos y herramientas personalizadas según el perfil del usuario.
Ventajas y Desventajas del Text to Speech
Ventajas técnicas, creativas y de productividad
- Ahorra tiempo en grabaciones.
- Permite trabajar en varios idiomas.
- Mejora la accesibilidad.
- Se integra fácilmente a sistemas y sitios web.
Limitaciones actuales del Text to Speech y posibles riesgos
- Algunas voces suenan aún artificiales.
- Problemas de pronunciación en idiomas o nombres raros.
- Posibles riesgos éticos con la clonación de voces reales.
Text to Speech para Creadores y Desarrolladores
El Text to Speech no solo representa una solución de accesibilidad o automatización, sino también una poderosa herramienta creativa para quienes producen contenido digital o desarrollan aplicaciones interactivas. Hoy en día, creadores de videos, educadores, programadores web y desarrolladores móviles pueden aprovechar el TTS para generar narraciones, interfaces habladas, asistentes virtuales y experiencias personalizadas sin necesidad de grabar audio manualmente.
Narradores automáticos para videos y redes sociales
Transforma guiones escritos en audios listos para usar en contenido digital, ideal para reels, shorts y videos educativos.
APIs y SDKs para programadores web y móviles
Servicios como Google Cloud TTS, Amazon Polly o ElevenLabs ofrecen APIs para integrar voz artificial en apps, juegos, sitios o bots.
Plugins y herramientas compatibles con WordPress
Existen plugins que convierten tus posts en audio o agregan funciones TTS a tu sitio, mejorando la accesibilidad y el engagement.
Uso para automatizar contenido con Text To Speech
Desde newsletters en formato podcast hasta audiolibros generados automáticamente, el TTS está redefiniendo la forma en que se crea contenido escalable y automatizado.
Conclusión
El Text to Speech ha evolucionado de ser una herramienta básica de accesibilidad a convertirse en una solución avanzada para la creación y automatización de contenido digital. Su integración en entornos educativos, comerciales, creativos y de desarrollo abre nuevas posibilidades para mejorar la productividad, ampliar el alcance de los mensajes y ofrecer experiencias más inclusivas. A medida que las tecnologías de síntesis de voz continúan avanzando —especialmente con la incorporación de inteligencia artificial generativa—, el TTS se perfila como una herramienta clave en el futuro de la comunicación digital. En próximos artículos, profundizaremos en herramientas específicas, APIs recomendadas, y cómo aplicarlas paso a paso en proyectos reales.

